Debugging neural networks initially seemed like an impossible challenge to me. We had an error that kept popping up and at first I put it down to floating point errors, or library errors or just a random number that got out of hand. Thanks to a couple of my supervisors and colleagues, I stuck at the debugging and with their help, we managed to find out what was going wrong. I figured I'd write a little about this as it might help to dispel a few myths about machine learning and also provide some programming help for folks
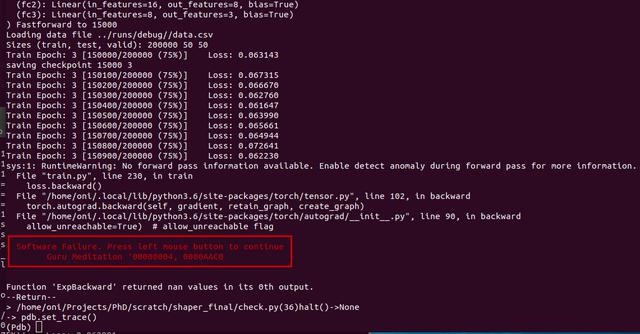
So this is the error we kept on getting:
sys:1: RuntimeWarning: Traceback of forward call that caused the error:
File "train.py", line 326, in
train(args, device)
File "train.py", line 227, in train
output = model(target, tpoints, w_mask, sigma)
File "/home/oni/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/oni/Projects/PhD/scratch/shaper_final/net.py", line 69, in forward
rot[1], rot[2], points.shape[0], sigma).reshape((1,128,128)))
File "/home/oni/Projects/PhD/scratch/shaper_final/splat_torch.py", line 190, in render
num_points = num_points, sigma = sigma)
File "/home/oni/Projects/PhD/scratch/shaper_final/splat_torch.py", line 221, in splat
torch.exp(-((ex - xs)**2 + (ey-ys)**2)/(2*sigma**2)), dim=0)
Traceback (most recent call last):
File "train.py", line 326, in
train(args, device)
File "train.py", line 230, in train
loss.backward()
File "/home/oni/.local/lib/python3.6/site-packages/torch/tensor.py", line 102, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/home/oni/.local/lib/python3.6/site-packages/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: Function 'ExpBackward' returned nan values in its 0th output.
Folks often warn about sqrt and exp functions. I mean they can explode creating really large or small numbers that might overflow or result in a divide by zero. Indeed, we are getting a warning about nan here so it's not a bad bet.
We can try using a clamp like torch.clamp to make sure the values don't exceed some set values:
model = torch.clamp(torch.sum(\
torch.exp(-((ex - xs)**2 + (ey-ys)**2)/(2*sigma**2)), dim=0),\
min = 0.0, max = 1.0)
A big topic this, determinism. It may surprise folks but it's perfectly possible to run a machine learning system deterministically. It sounds obvious when you say it out loud, but it most certainly can be done. Same data in, same losses out. If we can get our network to run in this way, we are making progress.
In pytorch, we need to set a couple of parameters:
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
Since we are using Python and Numpy as well, we need to set the same random seeds:
np.random.seed(0)
random.seed(0)
Also, any shuffling of the datasets and batches needs to be turned off too!
I use PyTorch these days. I've used Tensorflow in the past before now and both seem pretty good. Pytorch has a few key features that help with debugging. To get the error above, we can use the autograd anomaly detection code.
with autograd.detect_anomaly():
inp = torch.rand(10, 10, requires_grad=True)
out = run_fn(inp)
out.backward()
Pytorch has one large advantage over Tensorflow when it comes to debugging - it creates it's graph on-the-fly. It's more dynamic. This means we can use our favourite debugging tool, the python debugger pdb.
Python's with statement is a fun little bit of syntactic sugar. I took a look at the autograd detect anomaly class and decided I could probably write a version of it that called pdb when it failed. It looks a little like this:
import colorama
import torch
import pdb
import traceback
from colorama import Fore, Back, Style
from torch import autograd
colorama.init()
class GuruMeditation (autograd.detect_anomaly):
def __init__(self):
super(GuruMeditation, self).__init__()
def __enter__(self):
super(GuruMeditation, self).__enter__()
return self
def __exit__(self, type, value, trace):
super(GuruMeditation, self).__exit__()
if isinstance(value, RuntimeError):
traceback.print_tb(trace)
halt(str(value))
def halt(msg):
print (Fore.RED + "┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓")
print (Fore.RED + "┃ Software Failure. Press left mouse button to continue ┃")
print (Fore.RED + "┃ Guru Meditation 00000004, 0000AAC0 ┃")
print (Fore.RED + "┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛")
print(Style.RESET_ALL)
print (msg)
pdb.set_trace()
I had a little fun with the error message because why not! Makes a dull job a little more interesting.
So when I add this to the loss.backward() call in my code, I'll get the pdb firing up when a runtime error occurs. From here I can interrogate everything from the python commandline. With this in place I can test the tensors in memory, even if they are on the GPU and find out where the problem is.
The pytorch anomaly detection uses the function torch.isnan which checks a tensor for the NaN or Inf result, setting a 1 when it finds either. You can then wrap this in a torch.sum and if any number greater than 0 appears, you know you've found a problem:
torch.sum(torch.isnan(x))
Yep! Turns out it's all to do with culling points that are outside our viewing frustum. It was indeed, the classic divide by zero. We can put code in place to make sure that never happens again.
So thanks to PyTorch's dynamic nature, it's isnan function, determinism and python's PDB we can get right down to where the bugs are. It took me far too long to get here, going down a few blind alleys, but in the end, good engineering will get you there.
